BERT-Large: Prune Once for DistilBERT Inference Performance

By A Mystery Man Writer
Compress BERT-Large with pruning & quantization to create a version that maintains accuracy while beating baseline DistilBERT performance & compression metrics.
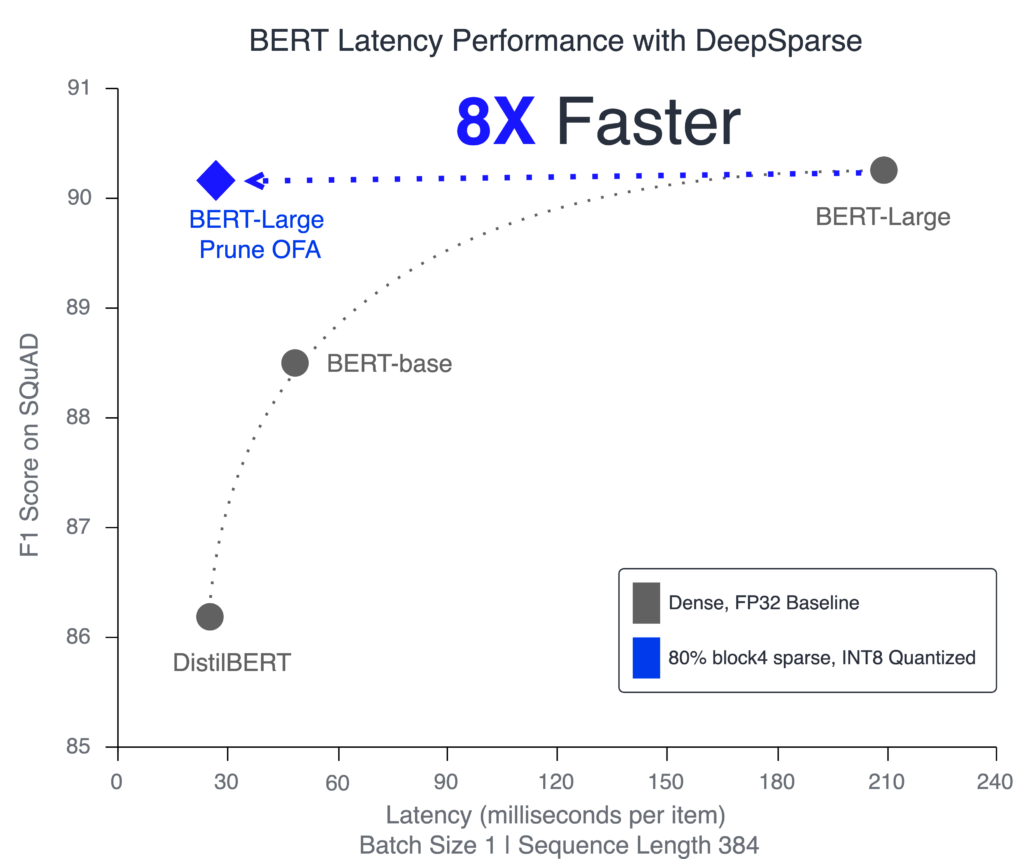
BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

arxiv-sanity

Jeannie Finks on LinkedIn: Uhura Solutions partners with Neural
Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

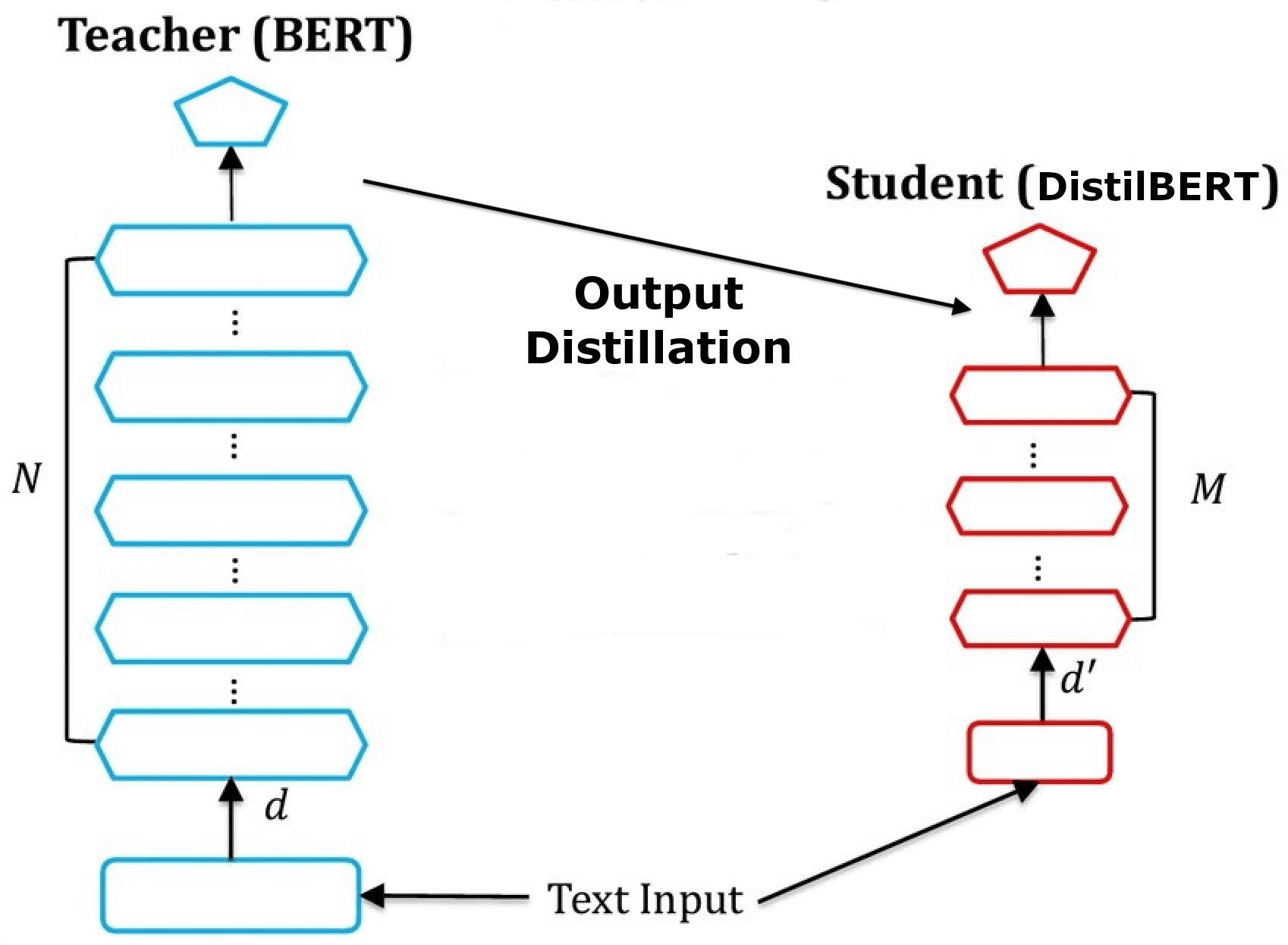
🏎 Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT, by Victor Sanh, HuggingFace
oBERT: Compound Sparsification Delivers Faster Accurate Models for NLP - KDnuggets

Dipankar Das on LinkedIn: Intel Xeon is all you need for AI
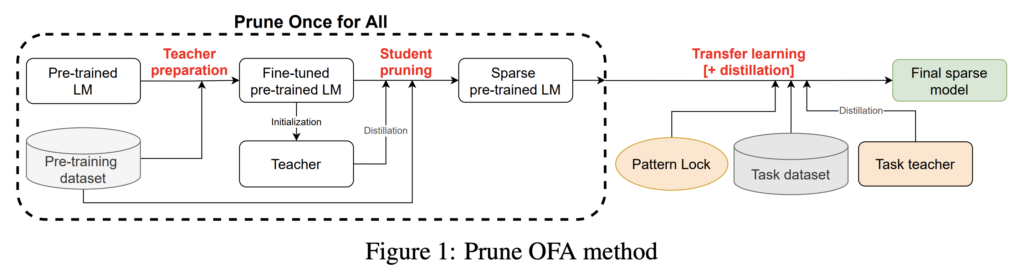
BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

PDF] GMP*: Well-Tuned Gradual Magnitude Pruning Can Outperform Most BERT- Pruning Methods

How to Compress Your BERT NLP Models For Very Efficient Inference

A survey of techniques for optimizing transformer inference - ScienceDirect

Qtile and Qtile-Extras] Catppuccin - Arch / Ubuntu : r/unixporn
- Dymo LabelWriter Label Extra Large Shipping 105 x 159mm Paper White Roll 220

- Color: Cardinal, Gogi, Gold, Red, Yellow, Size: 0~3-Months, 1X~Large, 2T, 2X~Large, 3T, 3X~Large, 3~6-Months, 4T, 4X~Large, 5T, 6~9-Months, Large, Medium, Small, X~Large, X~Small, Youth-Large, Youth-Medium, Youth-Small, Youth-X~Large, Youth-X~Small

- Capezio womens Team Basic Long Sleeve Leotard X-Large Royal

- Moors World of Sport🇿🇼 on X: Tag someone who needs to see this

- Extra Large Layered Beach Bag Tote Bag Zipper Side Pockets - Temu

- This post features amazing photos of trendy Ankara shorts you can rock for casual outting such …

- Bivik Jeans Loja Oficial Atacado

- Womens Bralette Aajustable Strappy Bras Ladies Comfort Soft Wire-Free Bra Push Up Plus Size Seamless Bowknot Underwear

- BRANTIC Women's Wirefree Padded Microfiber Nylon Elastane Stretch Full Coverage Multiway Styling T-Shirt Bra with

- PRIMA-160 (STRETCH) - STRETCH FABRICS
