RedPajama replicates LLaMA dataset to build open source, state-of-the-art LLMs

By A Mystery Man Writer
RedPajama, which creates fully open-source large language models, has released a 1.2 trillion token dataset following the LLaMA recipe.

Open source large language models: Benefits, risks and types - IBM Blog

2023 in science - Wikipedia

RedPajama: New Open-Source LLM Reproducing LLaMA Training Dataset of over 1.2 trillion tokens

RedPajama Reproducing LLaMA🦙 Dataset on 1.2 Trillion Tokens, by Angelina Yang

RedPajama - Llama is getting Open Source!
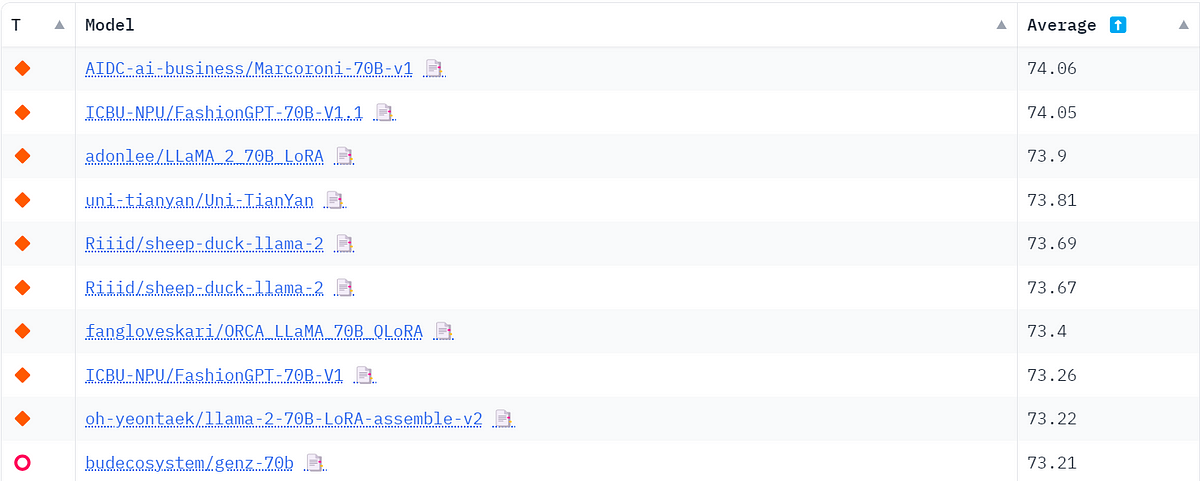
List of Open Sourced Fine-Tuned Large Language Models (LLM), by Sung Kim

Cloud Intelligence at the speed of 5000 tok/s - with Ce Zhang and Vipul Ved Prakash of Together AI
Llama 2: The New Open LLM SOTA (ft. Nathan Lambert, Matt Bornstein, Anton Troynikov, Russell Kaplan, Whole Mars Catalog et al.)

Why LLaMA-2 is such a Big Deal
GitHub - dsdanielpark/open-llm-datasets: Repository for organizing datasets and papers used in Open LLM.
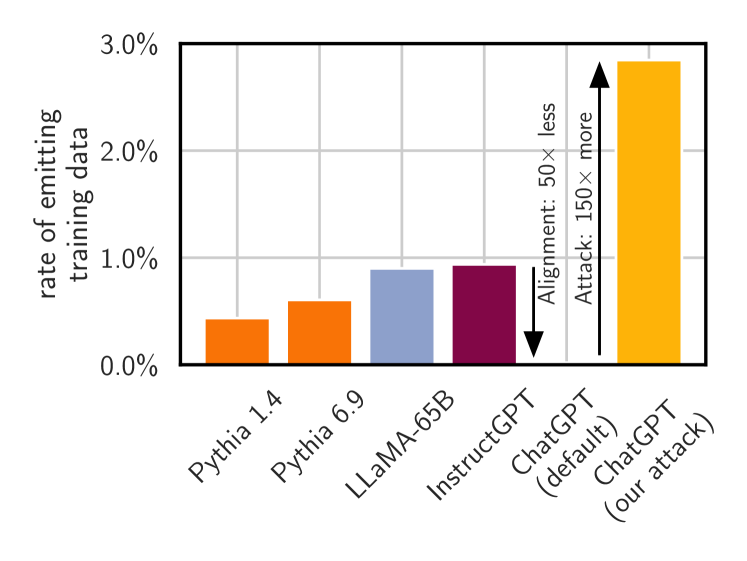
2311.17035] Scalable Extraction of Training Data from (Production) Language Models

今日気になったAI系のニュース【23/4/24】|shanda

Inside language models (from GPT to Olympus) – Dr Alan D. Thompson – Life Architect

Cameron R. Wolfe, Ph.D. on X: LLaMA-2 outlines the remaining limitations of open-source language models well. Put simply, the gap in performance between open-source and proprietary LLMs is largely due to the

Timeline of computing 2020–present - Wikiwand









