Monday, Jul 08 2024
We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on
By A Mystery Man Writer

PDF) How to Fine-Tune Vision Models with SGD

We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on
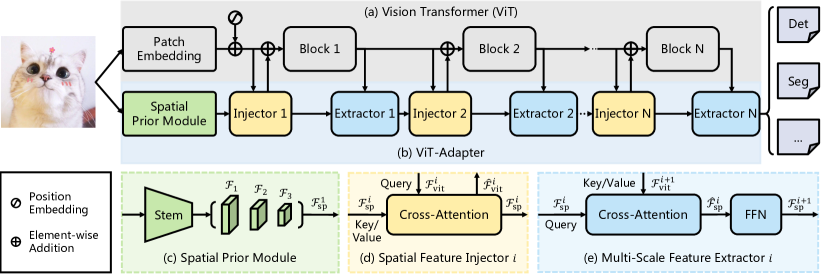
2205.08534] Vision Transformer Adapter for Dense Predictions
PDF) Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives

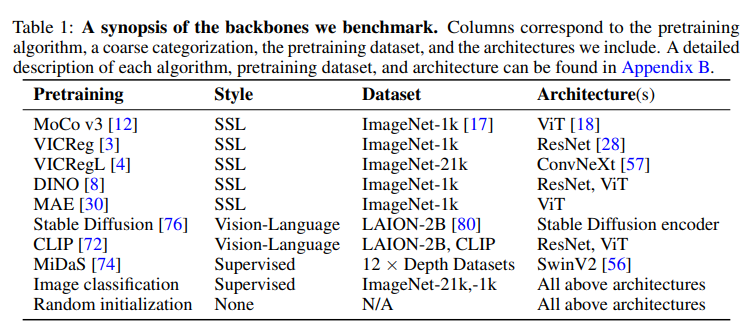
Ananya Kumar's research works Stanford University, CA (SU) and other places
The Computer Vision's Battleground: Choose Your Champion

D] Why Vision Tranformers? : r/MachineLearning

Robotics, Free Full-Text

2304.12210] A Cookbook of Self-Supervised Learning
Related searches








©2016-2024, doctommy.com, Inc. or its affiliates