Monday, Jul 08 2024
Red Pajama 2: The Public Dataset With a Whopping 30 Trillion Tokens

By A Mystery Man Writer
Together, the developer, claims it is the largest public dataset specifically for language model pre-training

Mandala #122 - TrendyMandalas
.jpg?width=700&auto=webp&quality=80&disable=upscale)
Data science recent news

RedPajama training progress at 440 billion tokens
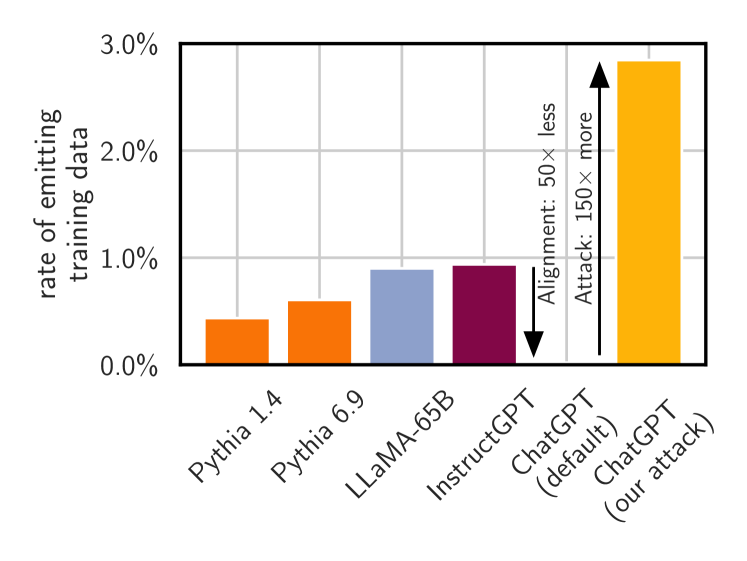
2311.17035] Scalable Extraction of Training Data from (Production) Language Models
.png?width=700&auto=webp&quality=80&disable=upscale)
ChatGPT / Generative AI recent news, page 5 of 21

RedPajama's Giant 30T Token Dataset Shows that Data is the Next Frontier in LLMs

RedPajama Reproducing LLaMA🦙 Dataset on 1.2 Trillion Tokens, by Angelina Yang

RedPajama-Data-v2: an Open Dataset with 30 Trillion Tokens for Training Large Language Models : r/LocalLLaMA
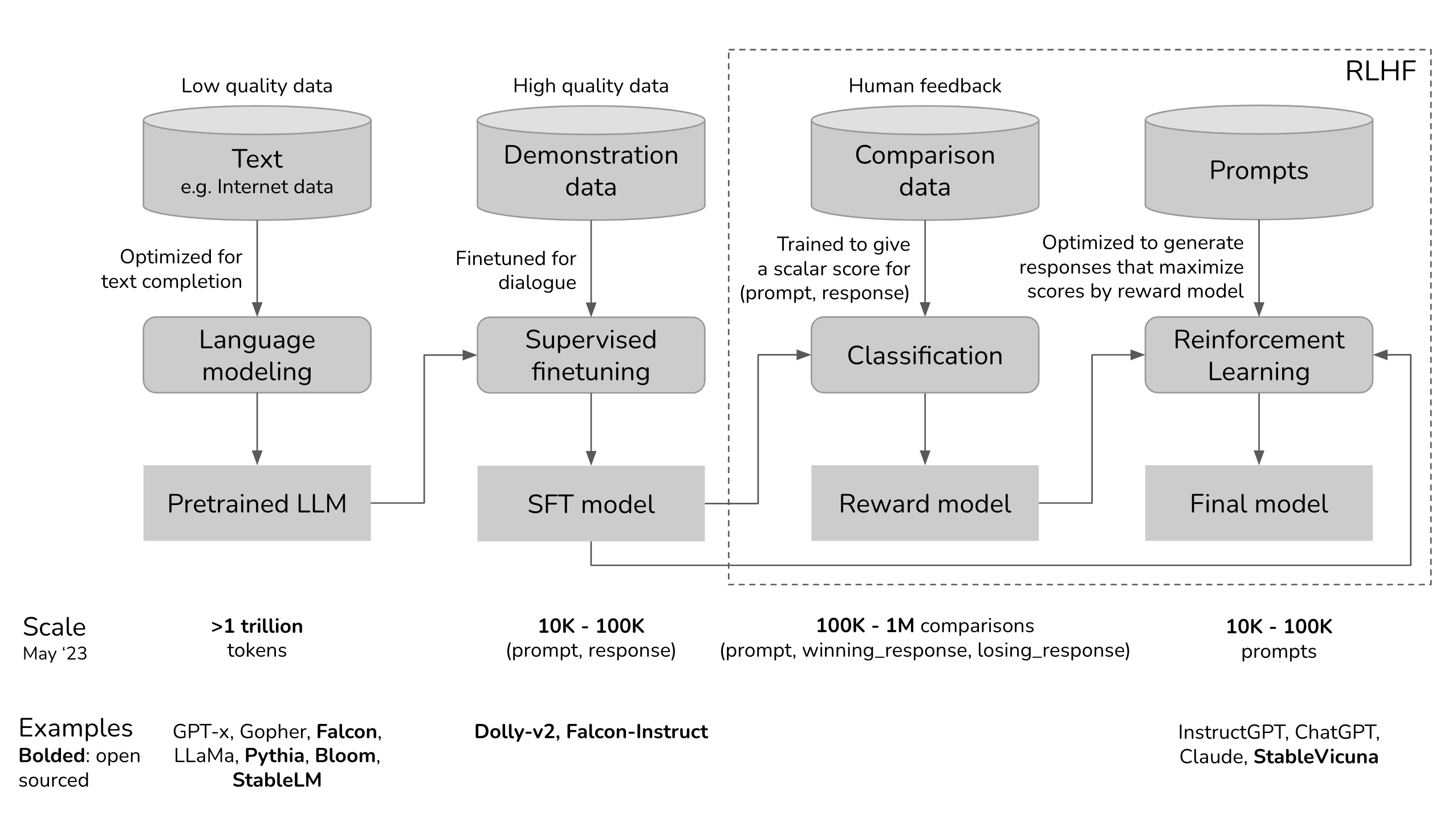
RLHF: Reinforcement Learning from Human Feedback
Related searches





Related searches
- Always ZZZ Disposable Period Underwear Overnight Absorbency Size S/M, 7 count - Baker's
- Mujer usa banda elástica para entrenar vestida con poses de ropa deportiva en una colchoneta de fitness en los hombros usa zapatillas de deporte de smartwatch de ropa deportiva posa afuera en

- Three CLASSY and ELEGANT Wide Leg Pants Outfits for Women Over 50

- The North Face Size W Large Women's Fleece Pants – Rambleraven

- The Total-Body Tabata Workout Anyone Can Do


©2016-2024, doctommy.com, Inc. or its affiliates