Spark Performance Optimization Series: #1. Skew

By A Mystery Man Writer
In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Spark Application Optimization for Performance using Qubole Sparklens

Handling Data Skew in Apache Spark, by Dima Statz

From Slow to Go: How to Optimize Databricks Performance Like a Pro - Beyond the Horizon
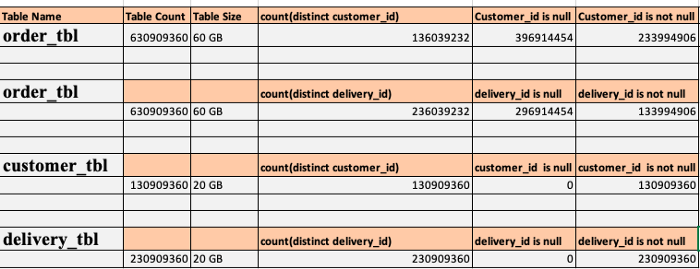
Optimizing the Skew in Spark
Optimizing the Skew in Spark

Apache Spark Performance is too hard. Let's make it easier

Advanced Spark Tuning, Optimization, and Performance Techniques, by Garrett R Peternel

List: Apache Spark, Curated by Luan Moreno M. Maciel

Optimizing Apache Spark Performance: Tackling Data Skew for Faster Big Data Processing, by VivekR

How to Optimize Your Apache Spark Application with Partitions - Salesforce Engineering Blog
List of cool blogs focussing on Spark performance optimization., by Sukul Mahadik





- Bunee Hand Woven Leather Sheets, 39 x 31 Panels, Tan

- Lawadka Autumn Winter Baby Tights for Girls Newborn Lace Pantyhose Casual Knitted Bow Clothes Accessories Cheap Stuff 2020 New

- Obituary, Danny Harris of Fowler, Kansas

- 448 Good Morning Greeting Stock Photos, High-Res Pictures, and Images - Getty Images

- Short Bamboo Nightgown – Sandmaiden Sleepwear
