Reinforcement Learning as a fine-tuning paradigm

By A Mystery Man Writer
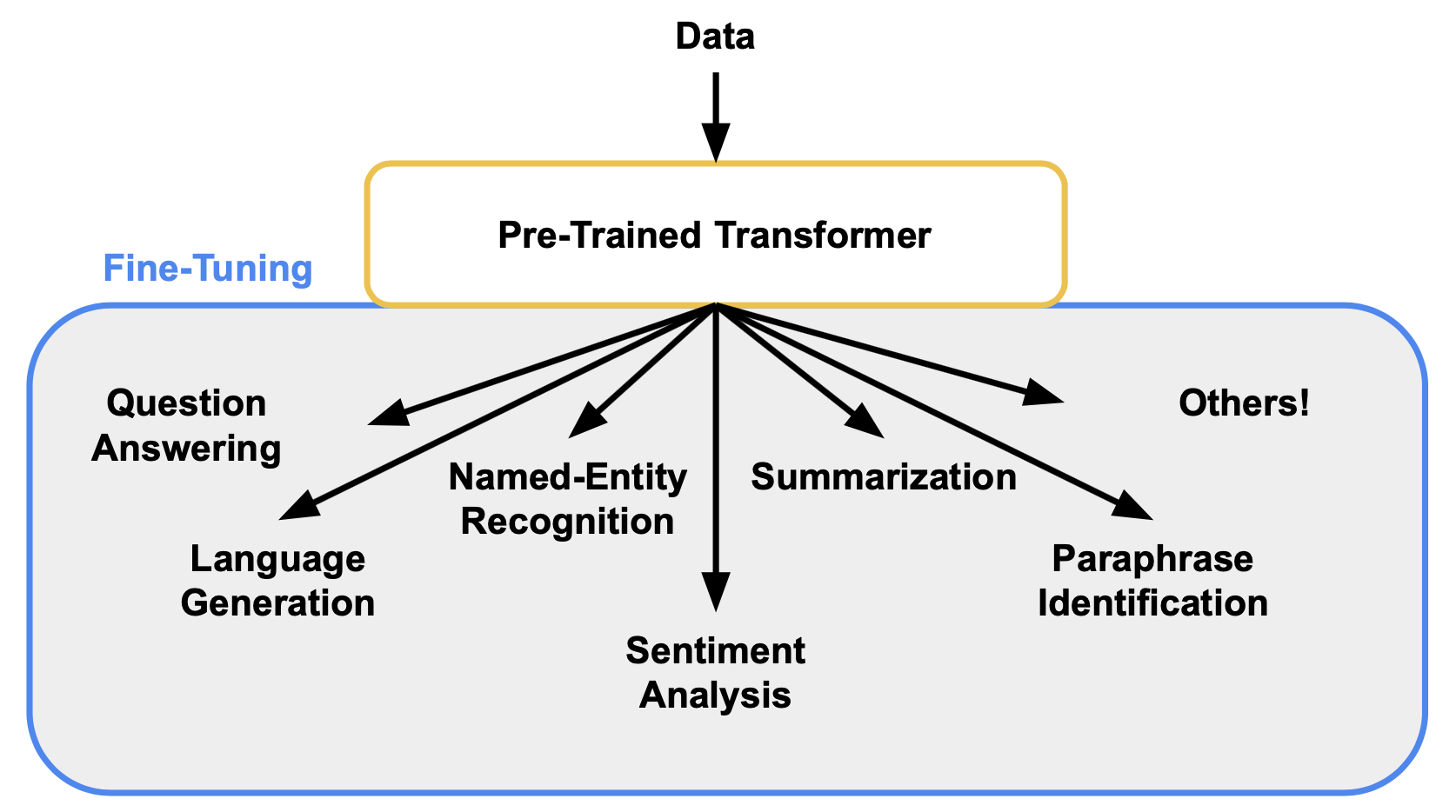
Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.

Deep reinforcement learning for engineering design through

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds, by Enes Bilgin, RL Agent
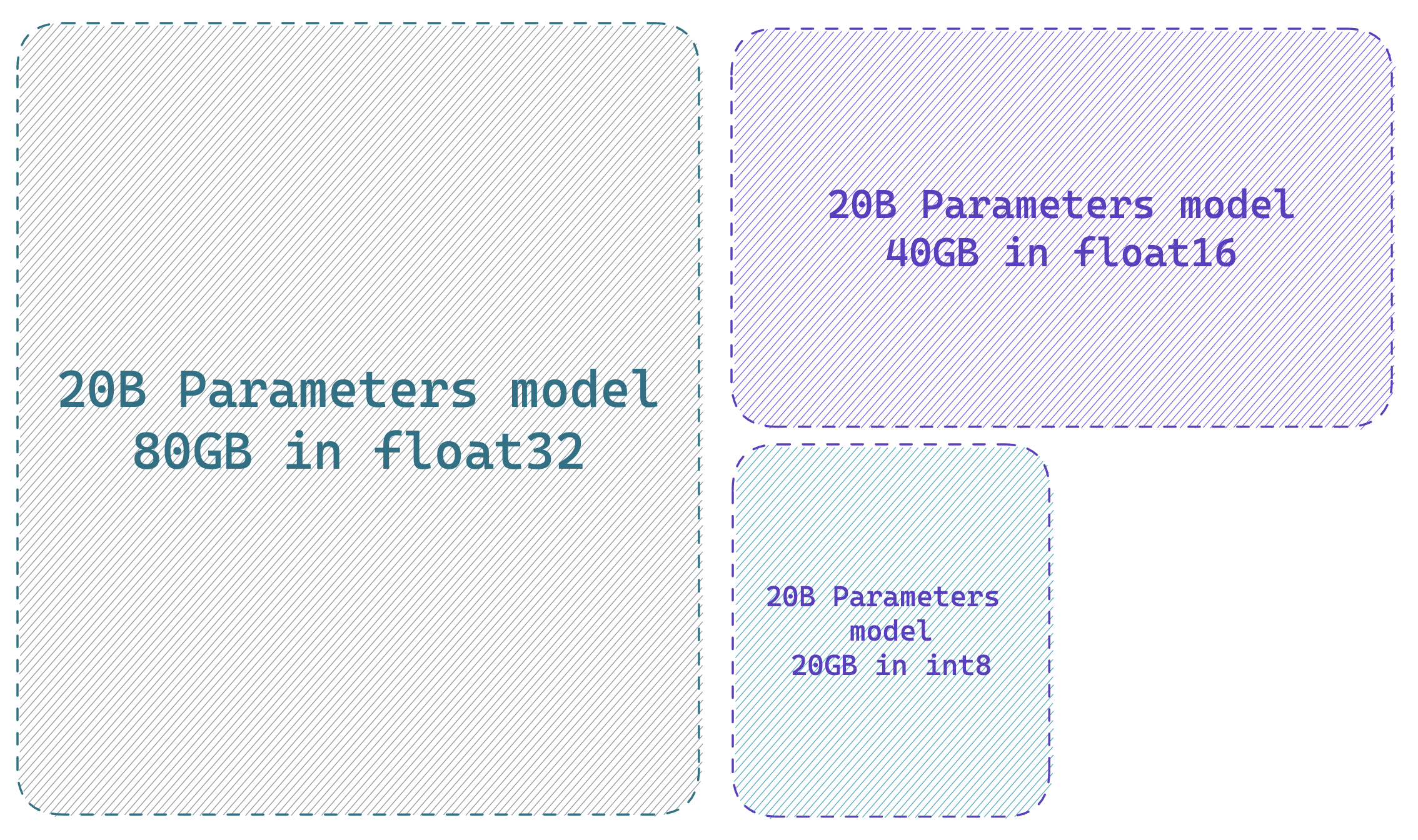
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

RLHF & DPO: Simplifying and Enhancing Fine-Tuning for Language Models
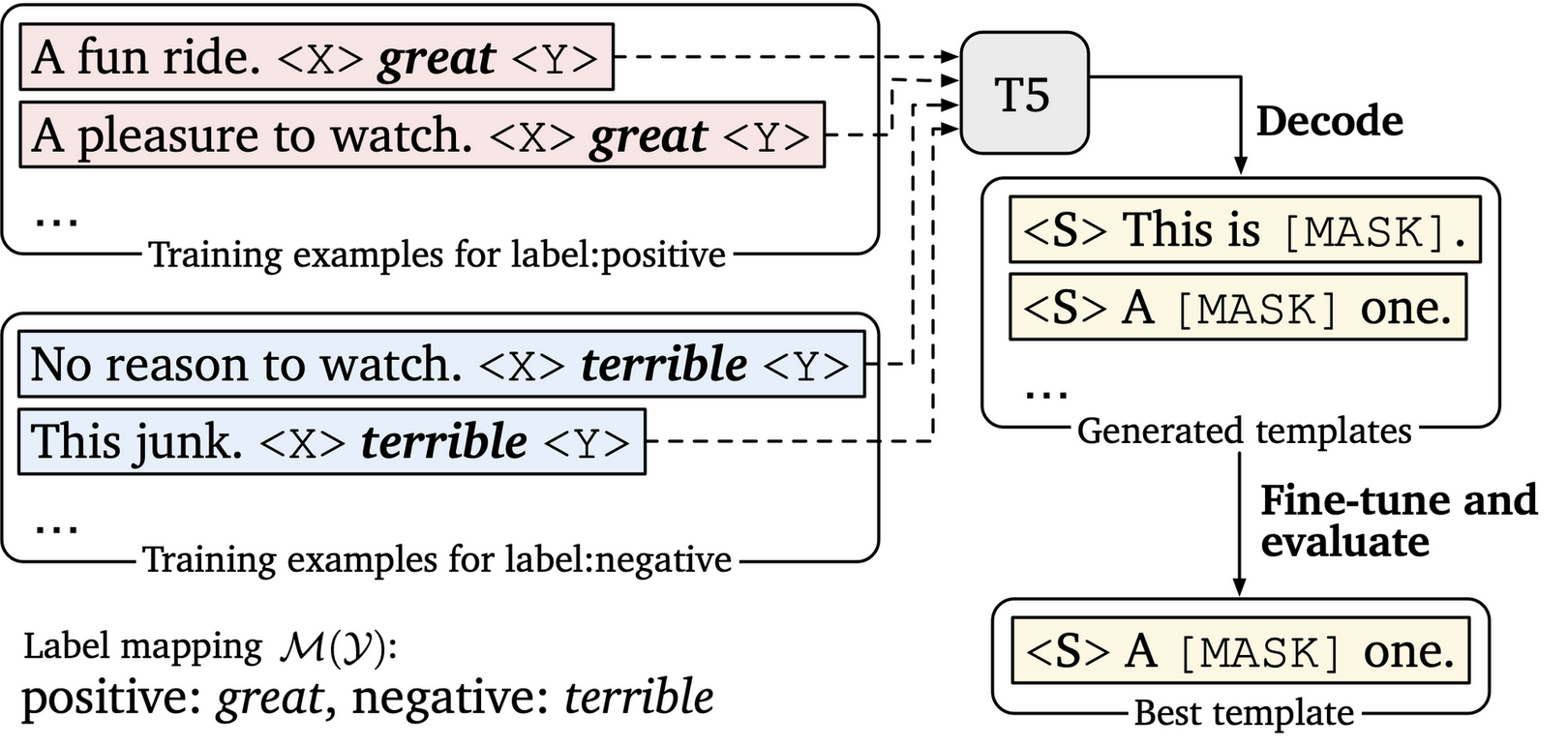
Prompting: Better Ways of Using Language Models for NLP Tasks
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

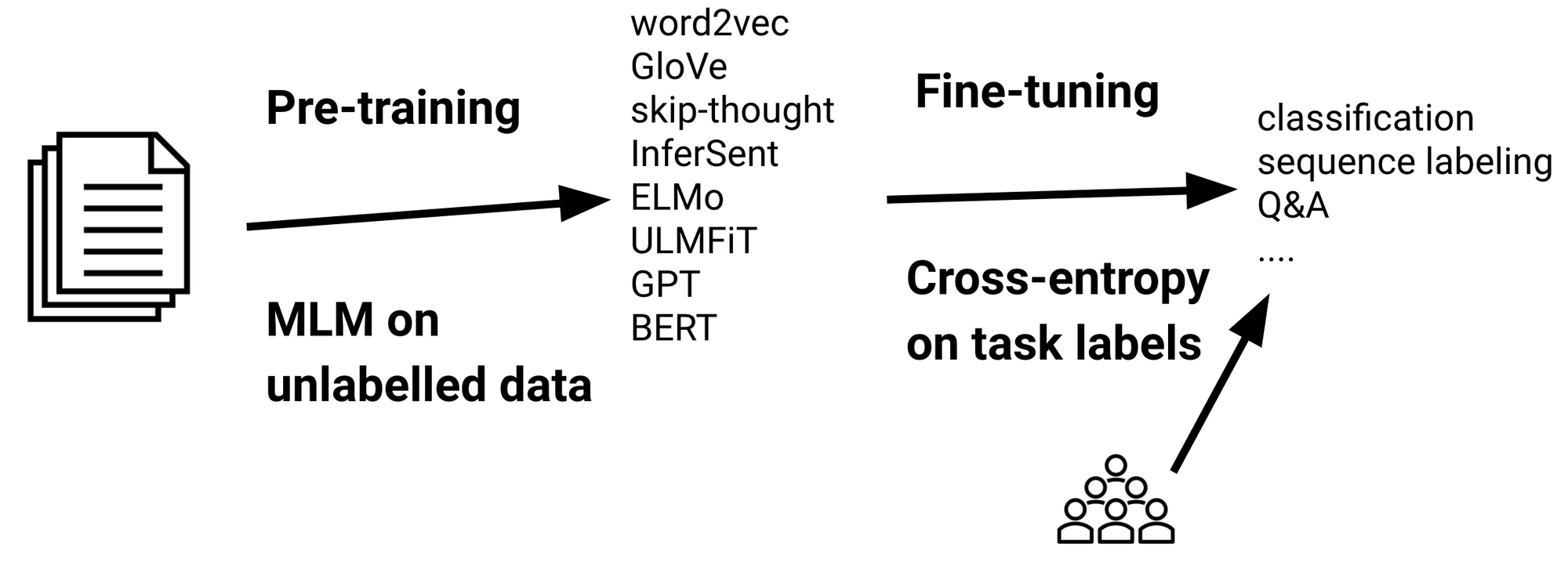
Google's Universal Pretraining Framework Unifies Language Learning

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds

paper-attachments.dropbox.com/s_03D8A88577B9611816
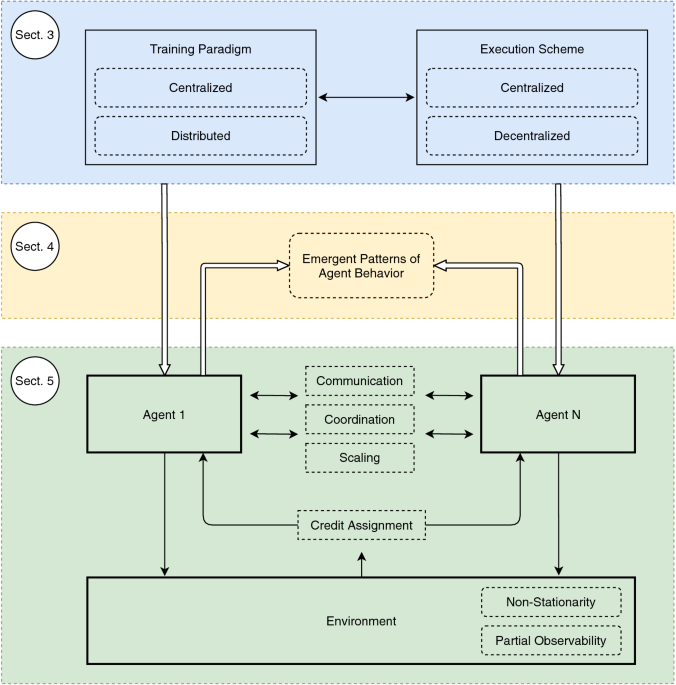
Multi-agent deep reinforcement learning: a survey
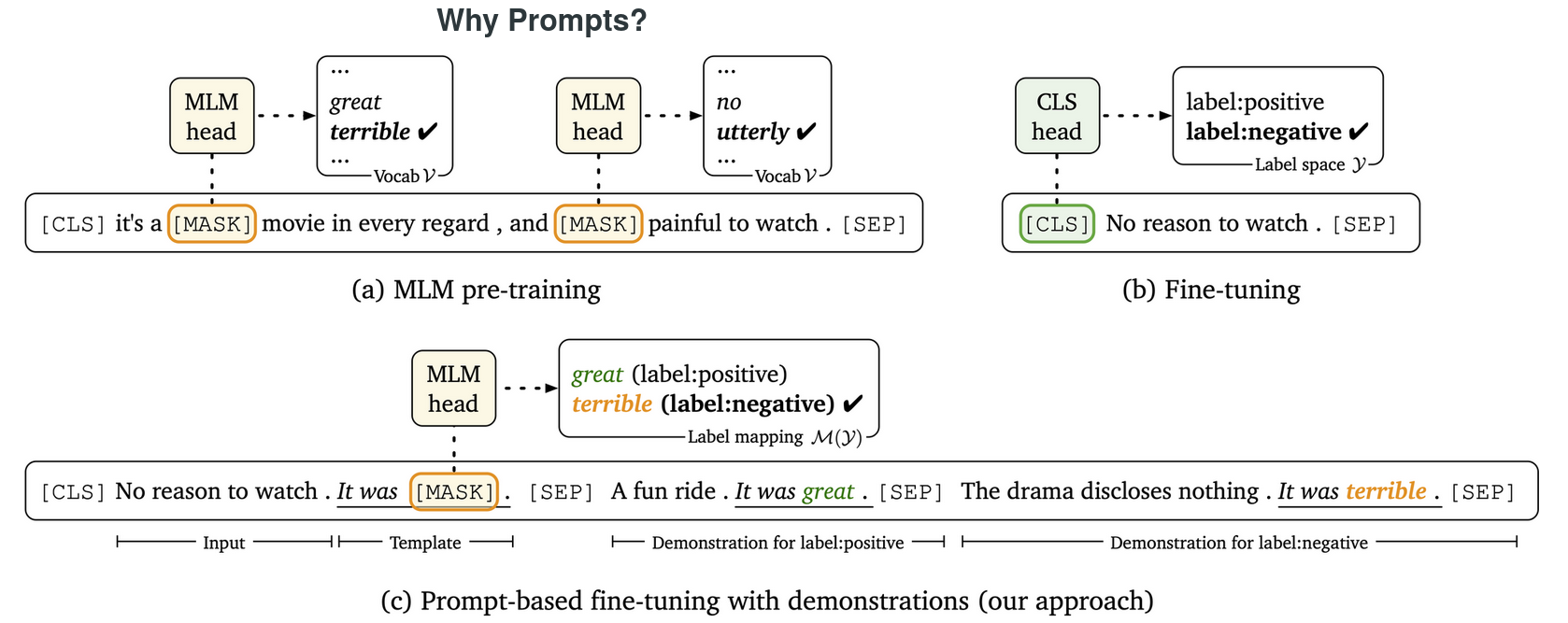
Prompting: Better Ways of Using Language Models for NLP Tasks
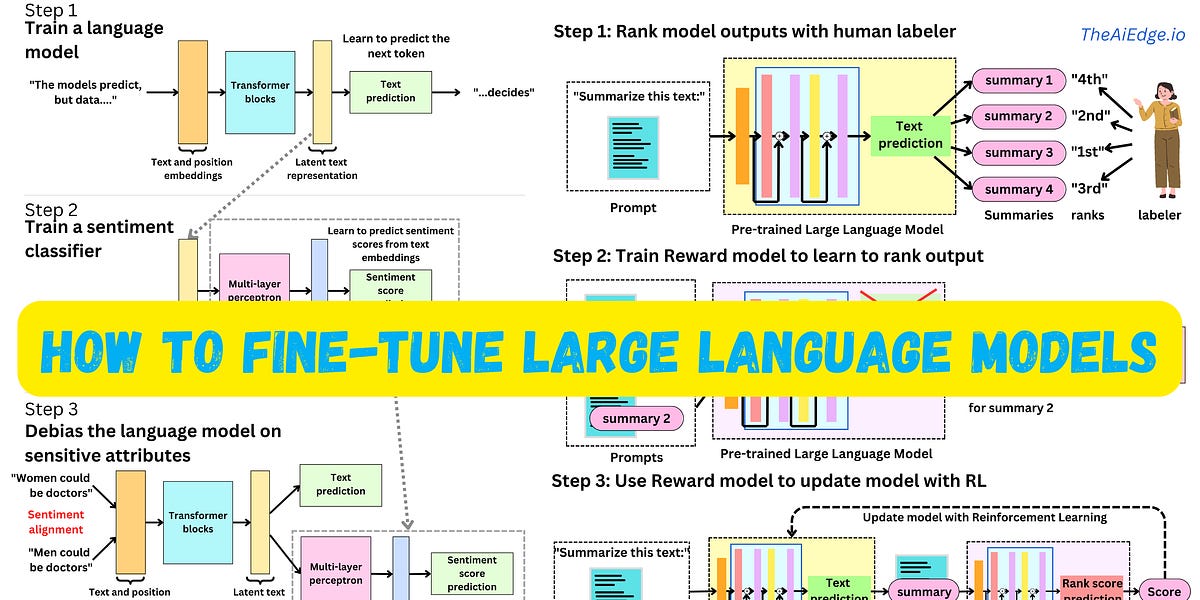
The AiEdge+: How to fine-tune Large Language Models with Intermediary models

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds
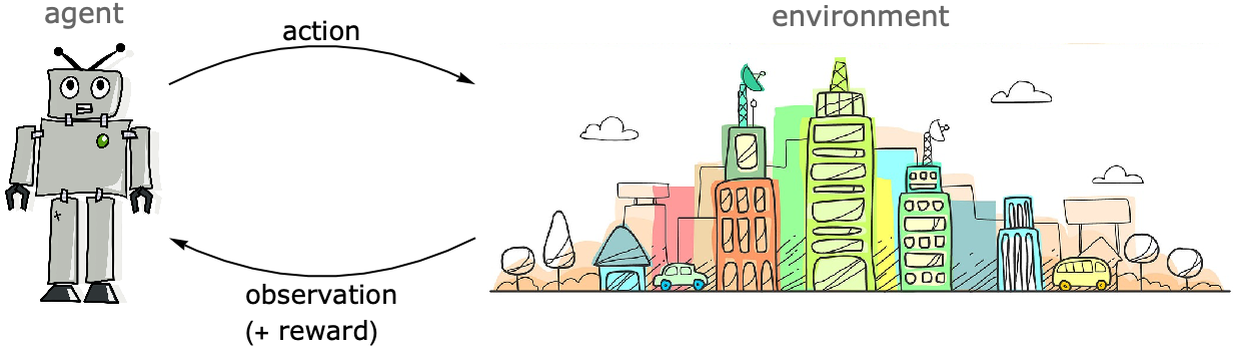
Machine Learning Paradigms - Introduction to Machine Learning

Electronics, Free Full-Text



- Super Thick Bra Pads Inserts Removable Breast Enhancers Push Up Bra Cups Paddings 3 Sets, Beige-6cm, X-Large

- CS-426 Standard Mesh Review

- Buy SUUKSESS Women Reflective High Waisted Running Leggings with Pockets Cross V Waist Yoga Pants (Black, S) at

- Spanx Thinstincts 2.0 Open-Bust Mid-Thigh Bodysuit

- Holiday Inn Express & Suites West Long Branch - Eatontown, West Long Branch (NJ)
