Language models might be able to self-correct biases—if you ask them

By A Mystery Man Writer
A study from AI lab Anthropic shows how simple natural-language instructions can steer large language models to produce less toxic content.

Articles by Arthur Holland Michel

How Language Models Can Fight Bias: A Revolution in AI Ethics, by Cezary Gesikowski

ChatGPT Replicates Gender Bias in Recommendation Letters

Guillermo Preciado (@gpreciado62) / X
Articles by Hannah Kerner
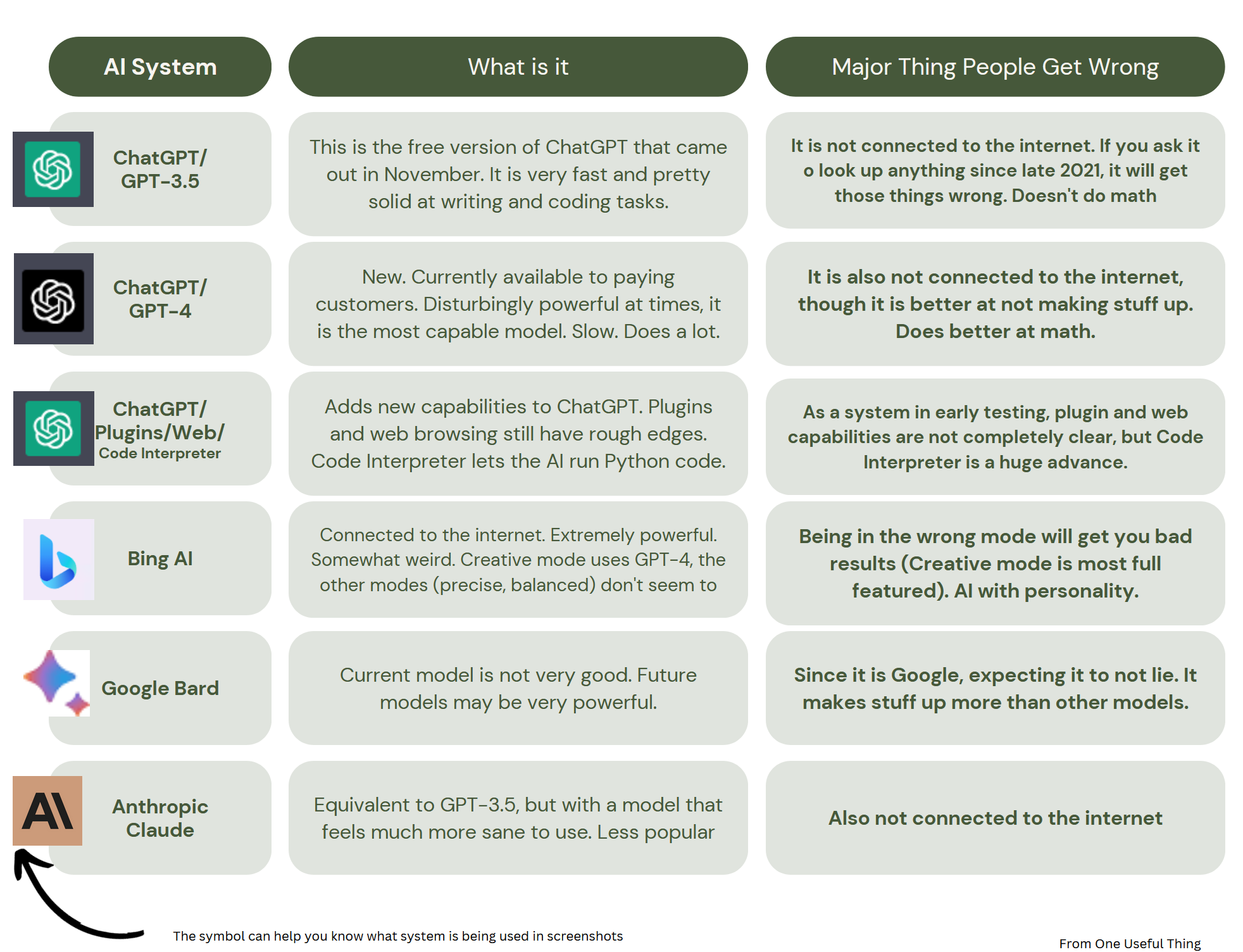
How to use AI to do practical stuff: A new guide
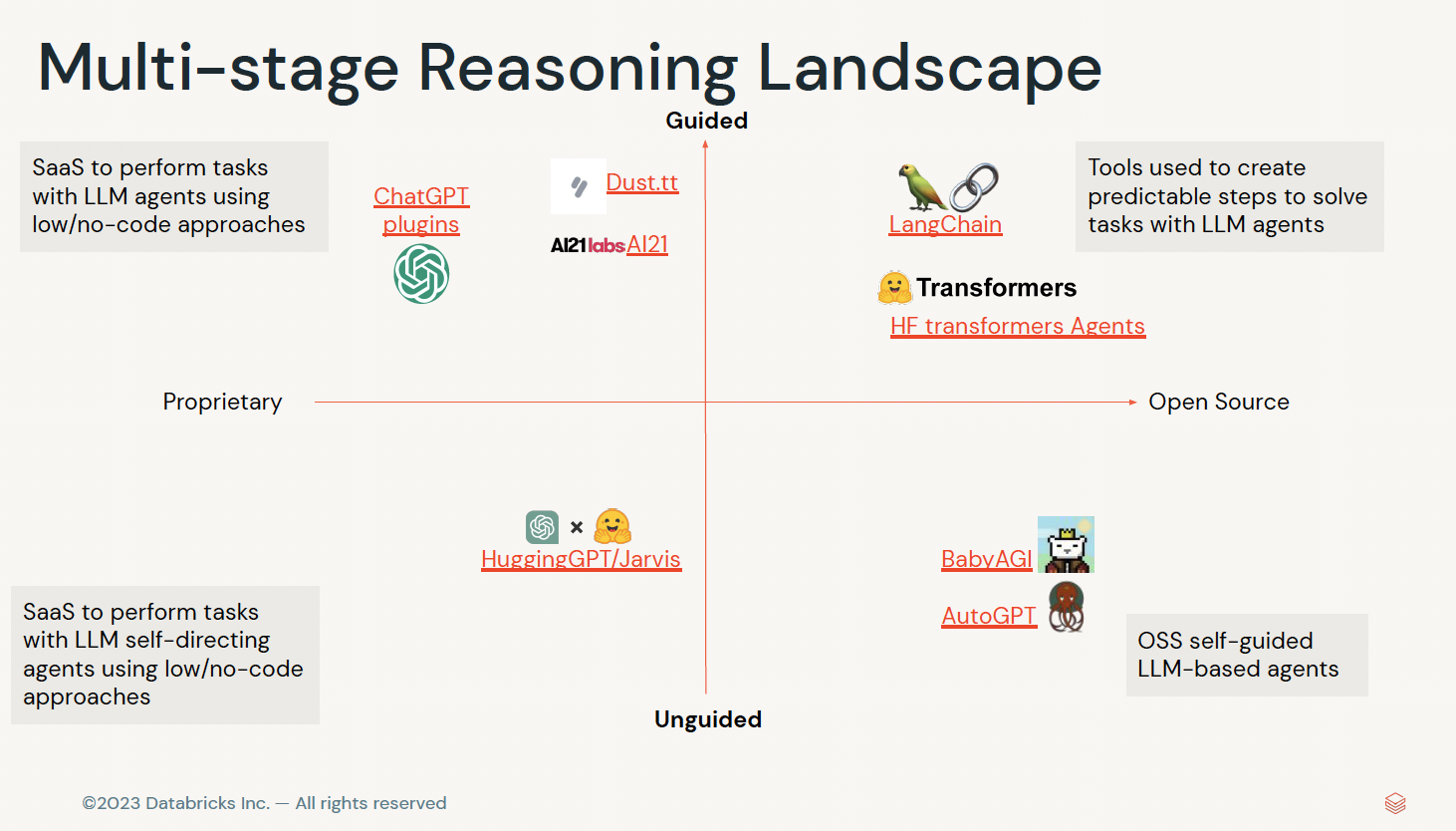
edX LLM Application through Production - ihower's Notes

Articles by Hana Kiros

Large pre-trained language models contain human-like biases of what is right and wrong to do

AI Weekly — AI News & Leading Newsletter on Deep Learning

Darren Tjan on LinkedIn: Language models might be able to self

Articles by Antonio Regalado

Why ChatGPT Is Getting Dumber at Basic Math - WSJ




- How to solve All Metal Puzzles

- Breast Lift San Antonio Voted #1 Best Plastic Surgeon

- Specialized Boa S3-snap Left Dial W/lace Blk/blk 19

- White Sequin Jumpsuit Plus Size Chic Lover - Plus Size Clothing

- Gotoly Shapewear for Women Scoop Neck Tank Tops Bodysuits Jumpsuits Waist Trainer Full Body Shaper Faja Colombianas(Beige X-Small-Small)
