Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference

By A Mystery Man Writer
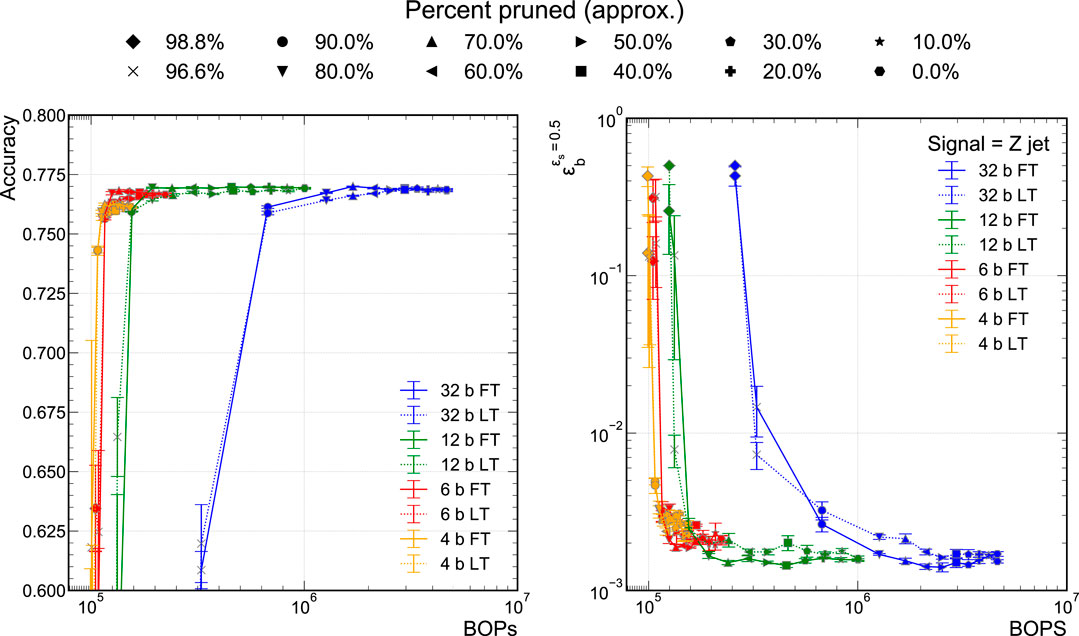
Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference

Loss of ResNet-18 quantized with different quantization steps. The

Frontiers in Artificial Intelligence Big Data and AI in High Energy Physics

Pruning and quantization for deep neural network acceleration: A survey - ScienceDirect

Deploying deep learning networks based advanced techniques for image processing on FPGA platform

Quantized Training with Deep Networks, by Cameron R. Wolfe, Ph.D.
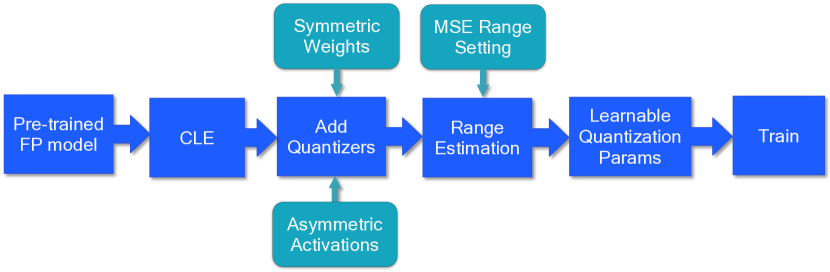
2106.08295] A White Paper on Neural Network Quantization
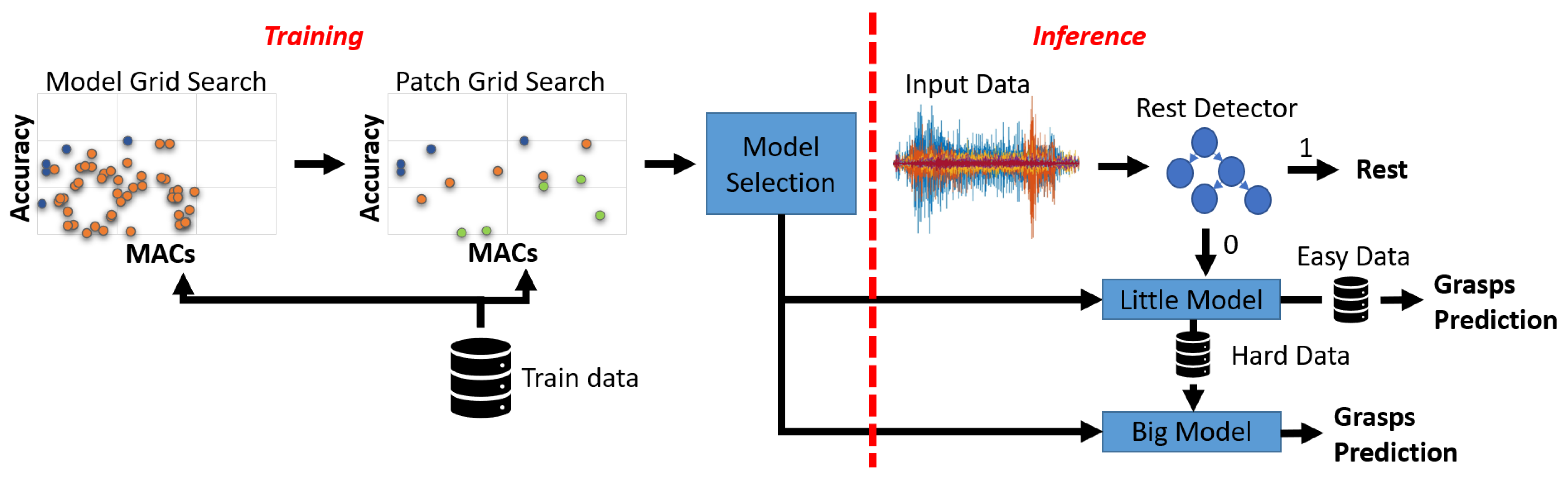
Sensors, Free Full-Text

PDF] Channel-wise Hessian Aware trace-Weighted Quantization of Neural Networks

A visualization of the loss surface for the pair of layers using one

Frontiers Quantization Framework for Fast Spiking Neural Networks
- The Strange Saga of the B-32 Dominator, The National WWII Museum

- Selina Solutions Concise Mathematics Class 6 Chapter 32 Perimeter and Area of Plane Figures download PDF

- Gothic Longline Bra - Finland

- HK Models 1/48 scale B-17G “Tape Up” review.

- HK Models 1/32 B-17G Flying Fortress Little Patches - Ready for Inspection - Aircraft





